雨滴合成器/A Raindrop Synthesizer
这学期的Audio Programming课写了一个雨滴合成器作为最终作业,期间因为种种原因代码改了好几个版本,现在的版本效果算是差强人意。虽然结果不是尽善尽美,整个迭代的过程还是值得记录的,如此也就有了这篇博客。
为什么想做雨滴合成器?
这学期的其中一个作业是复现一篇1984年的physcally-based synthesizer (Karplus-Strong model). 简单来说,就是基于物理规则对声音进行建模,例如市场上有物理建模钢琴pianoteq,据说声音可以媲美昂贵的采样音源,而且体积非常小巧。对钢琴来说,物理建模就需要包括琴槌的属性,琴槌击弦发声的过程,以及声音在钢琴腔体内的传播等等。每一个步骤都会涉及到非常复杂的推导过程,所以不适合数学不好的我(悲)。
我觉得这种物理建模合成器非常神奇,不需要预录好的audio sample也可以产生出非常真实的声音,因此,我想试一试能不能做一个简单的物理合成器。然后我就选择了雨滴合成器。
过程
既然想要基于物理,就得找到合适的公式。在参考了一圈之后,我找到了这篇04年的论文。
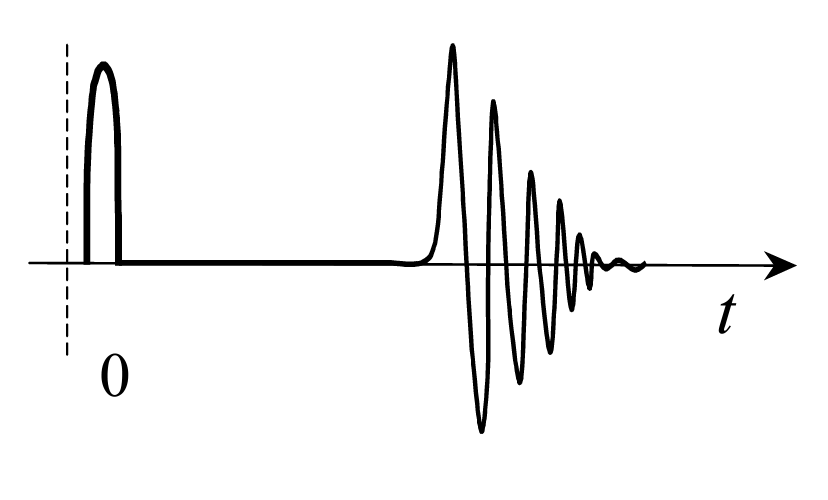
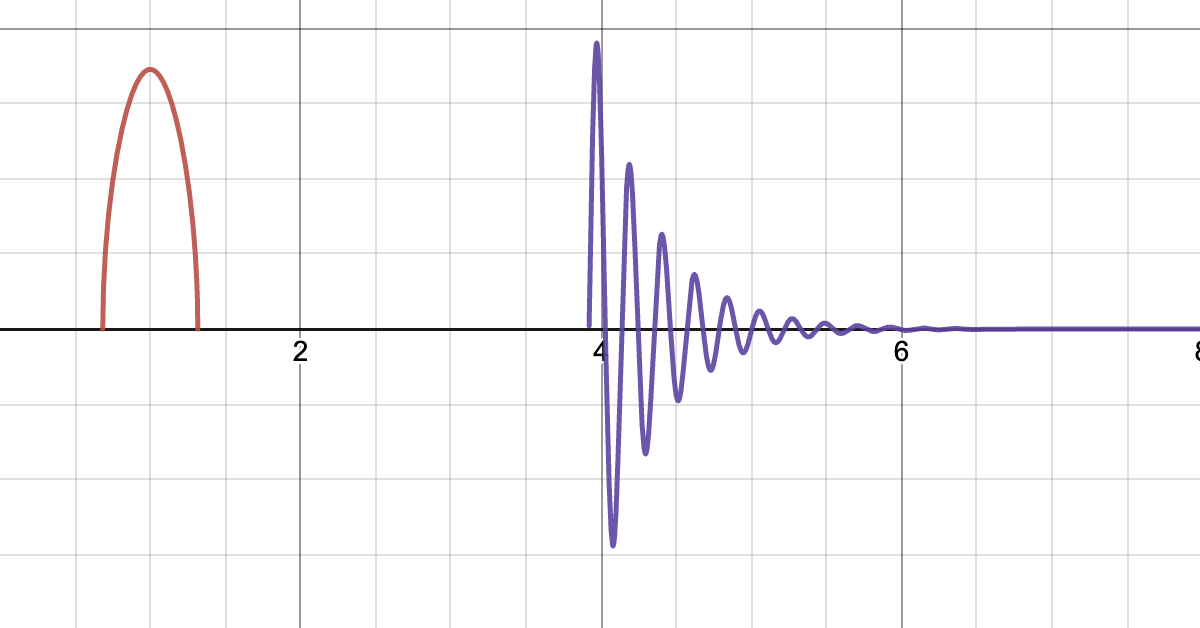
其中,作者给出了以上的波形图。雨滴的波形通常可以分为两个不同的阶段:第一阶段,水滴打到硬表面。第二阶段,水滴打到湿表面,逐渐衰减。整个过程约持续10-20 ms。
其中,第一阶段的波形由以下公式给出:
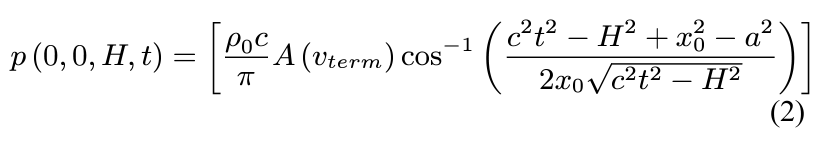
其中,p代表在t时间点,H的高度上雨滴产生的声压,而右侧参数多到让人直接昏厥。虽然形式看起来很复杂,但是大部分都是固定的参数。例如c代表声音的传播速度,v_term代表雨滴的终止速度等等。假设聆听者的高度H固定为1.85m (是谁的身高?),那么整个函数其实只和时间t有关,我们只需要给定一个时间,函数就会返回声压级,这个声压级也就可以近似认为是这个时间点的响度。
第二阶段如下给出:
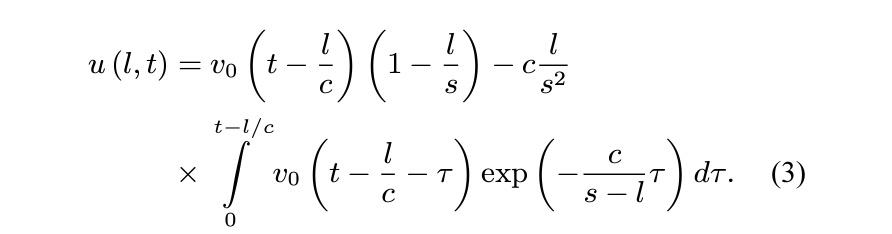
给定时间
t和某个水波形状相关参数l,这一时间点的声压如上,对应波形图的上下来回并衰减的部分。
有了公式,然后呢?
有了公式之后,只要把这些公式写下来,给定时间,返回值就可以了吧?不行。
基于物理的建模虽然很精确,但是这得基于一个前提:参数是准确的。如果参数不准确,那么结果自然也不准确。而我恰好不知道怎样是好的参数。
例如我第一次应用第一阶段的公式的时候,整个第一阶段只能产生3-4个sample(以44100Hz的sample rate为例,也就是只有0.06 ms),仅仅三四个sample哪里有声儿啊。同理,第二阶段参数设置也很复杂。考虑到一个水滴的完整声波应该有10-20 ms,我显然搞错了参数,但我也不知道从哪个开始改起。
简化
现有公式参数太多了,让我不知从何下手。但至少我知道我波形图应该长什么样子,也知道整体的时长为10-20 ms。我们可以直接使用参数更少的波形去近似复杂的公式,同时让结果尽可能接近给定的波形图。
在这样的想法下,第一阶段的函数被简化为了:
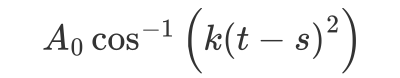
其中
A0用于控制响度,k用于控制波形的宽度,而s用于控制水滴发声的时间。
同理,第二阶段的函数也被简化成了:
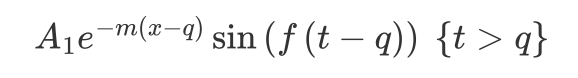
其中
A1用于控制响度,m用于控制响度衰减的速度,f用于控制衰减的频率,q用于控制水滴发声的时间。
这是近似后产生的波形图,和给定的波形图是比较相似的。而且这一近似模型参数较少,易于控制。所以在实现的时候我就采用了这个近似模型。
实现中遇到的问题
前景提要:音频计算通常是以block_rate为单位,一个block通常含有512个samples,在audio programming中每一个sample通俗理解就是一个时间点的数值。计算时基本上是一次性计算512个samples,然后再播放这512个samples,以此往复。
- Amplitude Normalize
既然是雨滴生成器,那一滴雨肯定不够。怎么说也得每秒来一千个水滴吧?我给每个雨滴设置了不同的起始时间,使得这些雨滴均匀分布在1秒内。尝试一番后,我试着输出每个时间点t(也就是一个sample)的数值,发现有不少的sample数值大于30或小于-5。通常来说,每个sample的result都应该被限制在[-1,1]之间,否则就没有意义。因此,我需要对所有的samples进行normalize。直接clamp/cutoff肯定不行,这样会损失掉samples之间相对大小的信息。我采取的方法比较简单,先记录下所有的sample数值,并找到其中绝对值的最大值,然后每个数除以这个值。
1 | void normalize(std::vector<float> &result) |
举个例子来说,{10.0,-20.0,-30.0}的结果在normalize之后应该是{1/3,-2/3,-1}。
这样做有一个问题,音频的计算通常是以block_rate / sample_rate 作为单位,也就是说需要在512/44100 秒内完成计算。==由于我无法提前得知1秒内的最大绝对值==,因此只能提前计算完1秒内所有的samples (44100个samples,每个sample可能有几百个水滴,需要在512/44100秒内完成计算),找到max_abs,然后再对所有的samples进行处理。显然CPU是没有这样的速度的,audio thread会被block,从而听不到任何声音。
倘若采取std::async的方式进行异步计算,即每512/44100秒内,根据用户给定的参数,计算新的44100个samples的数值,当计算的thread完成后,现在的samples就会被替换成新的samples。
1 | //每个block_rate完成如下计算 |
由于不知道什么时候可以计算完(通常都比较慢),用户变更参数就会变得非常不灵敏,通常都得等上一段时间才会播放最新计算出来的samples。
现在我们陷入了两难,不计算1秒内所有的samples,我就不能知道最大绝对值,也就不能normalize,提前计算好1秒内所有的samples又实在太慢。有没有什么两全其美的办法呢?用running max替代global max。
1 | #每个sample time(1/44100秒) 进行如下计算 |
之前我们需要预计算是因为我们希望使用global max进行normalize。假设我们采用running max,那么就不需要提前计算1秒的所有samples,我们只需要每个时间点计算出一个值,更新running max,再除以running max就可以了。
- Inter-block Cutoff
由于不需要知道global max,我们计算的逻辑已经从每个block_rate (512/44100秒)计算1秒的所有samples (44100个)变成了计算每个block 的所有samples (512个)。这个量级基本可以实现实时计算了。但另一方面,由于每block_rate就会计算出512个新的samples,samples的更新速度非常快。那么就有可能存在以下的情况:
在上一个block中,有一个水滴在还在第一阶段,并且没有结束第一阶段,所以按理来说,到下一个block的时候,上一个水滴应该继续第一阶段的波形。但是==由于计算一个新的block时会重新初始化所有的水滴(reset水滴的timer)==,那么不同的block之间就变得完全无关了。可能上一个block中某个水滴还在第一阶段,一到下一个block这个水滴却还没有进入第一阶段。这种跨越block时的不连贯我暂且称其为inter-block cutoff 。我总觉得这里应该配张图才能更好解释这个概念,不过后面再说吧。
总之作为结果,这种不连贯会产生一种click的效果,听起来比较像鼠标按左键的声音。
既然计算新的block时初始化所有的水滴会导致这样的不连贯性,那么只要不初始化不就行了吗?之所以我们需要初始化所有的水滴,是因为如果不初始化,按照当前设置的参数,所有的水滴只会均匀分布在0-1s的时间轴上,因而一旦时间超过1秒,所有的水滴都不会产生声音。而初始化所有的水滴就能reset时间轴,从而能够实现持续播放的效果。
想要保持连贯,那么我们就需要保证在新的block开始时,每一个水滴的timer和上一个block结束时的timer只差了一个sample_step(1/44100秒),也就是上一段中提到的“不初始化”。那么我们该怎样实现持续播放呢?注意到所有的水滴都只有可能在[0,1]的区间上发出声音,如果我们需要让模拟器持续发出声音,那么每个水滴的时间轴就需要在这个区间上循环。如果重置时间轴发生在第一个阶段中或者第二个阶段中,那么就会产生cutoff,我们只需要确保重置时间轴时,水滴已经结束第一或者第二阶段(即不发出声音),此时,由于重置前后结果都为0,也就没有了cutoff带来的click效果。
可以控制的参数:
在这个插件中,你可以调整这些参数来产生不同的效果
Gain - Overall audio gain
Density - How many drops in one second
Freq Coeff - Controls overall frequency
Interval Coeff - Controls average duration of drops
Noise Level - White noise level
High pass filter and Low pass filter
- 12dB / Oct
应用:
其实在写代码之前,用Max做了一个雨声生成器的原型,思路来自于以下这篇文章。里面提到procedural的雨声可以由高频的烧水声+中频的烧水声+噪声+单独的水滴声组合而成。现在雨滴合成器可以通过调整参数实现一层烧水声+一层噪声的组合。理论上只要开2-3个雨滴合成器的instance,调整合适的参数后再按一定比例混合起来,就可以实现更为逼真的程序化的雨声了。
https://blog.audiokinetic.com/zh/generating-rain-with-pure-synthesis/
后面可能也许会考虑直接在插件里面写两个instance,然后用户可以直接控制每个instance的参数。另一方面还希望可以加一点UI,以及莫名出现的seg fault也需要debug。
最后:
这是小玩具的地址,需要用到JUCE submodule,有兴趣的可以试一试。